Cookbook: Langfuse JS/TS SDK
JS/TS applications can either be traced via the low-level Langfuse JS/TS SDK, or by using one of the native integrations such as OpenAI, LangChain or Vercel AI SDK.
In this notebook, we will walk you through a simple end-to-end example that:
- Uses the core features of the Langfuse JS/TS SDK
- Shows how to log any LLM call via the low-level SDK
- Uses integrations that are interoperable with low-level SDK
- LangChain integration
- OpenAI integration
For this guide, we assume that you are already familiar with the Langfuse data model (traces, spans, generations, etc.). If not, please read the conceptual introduction to tracing.
Example trace that we will create in this notebook:
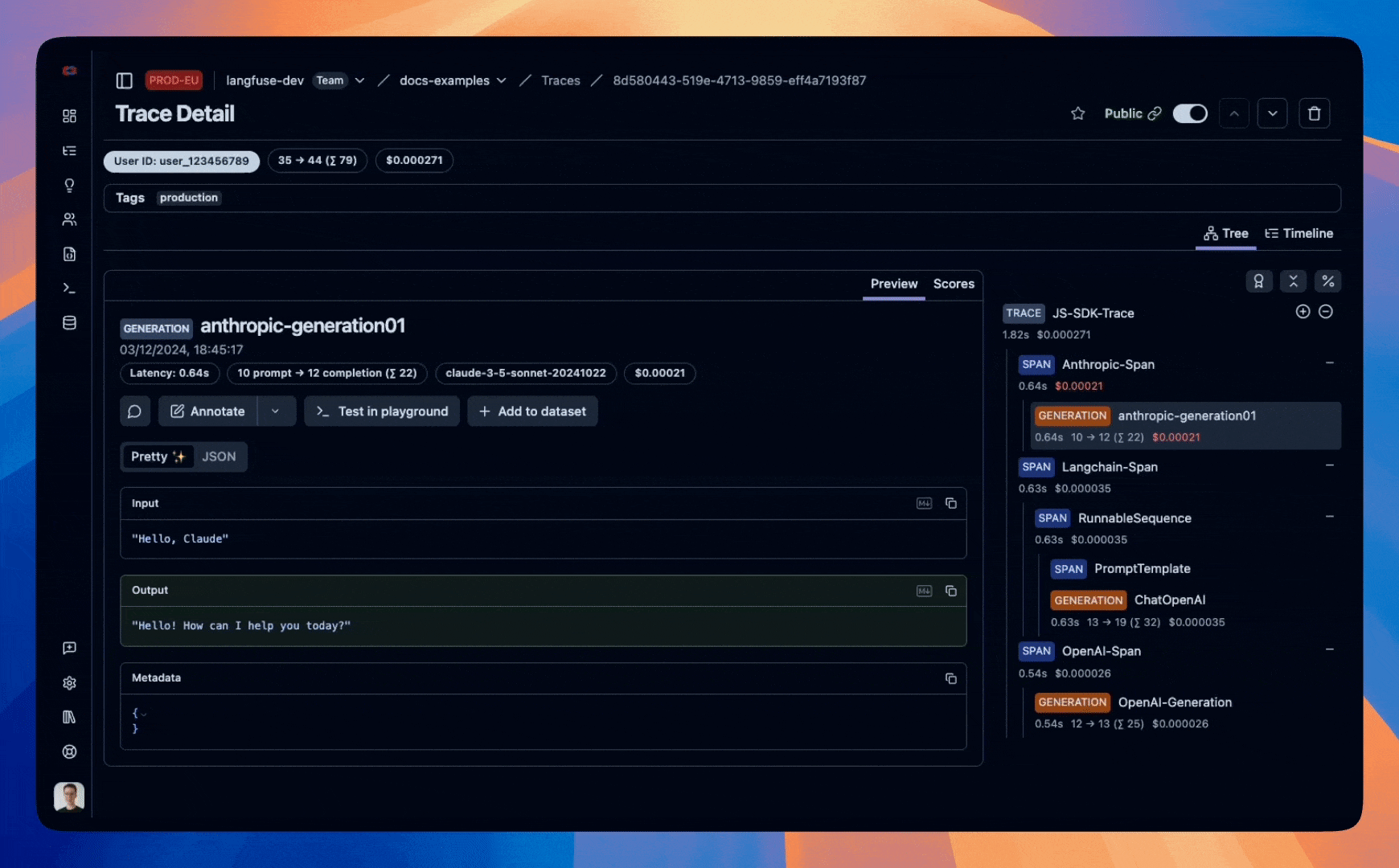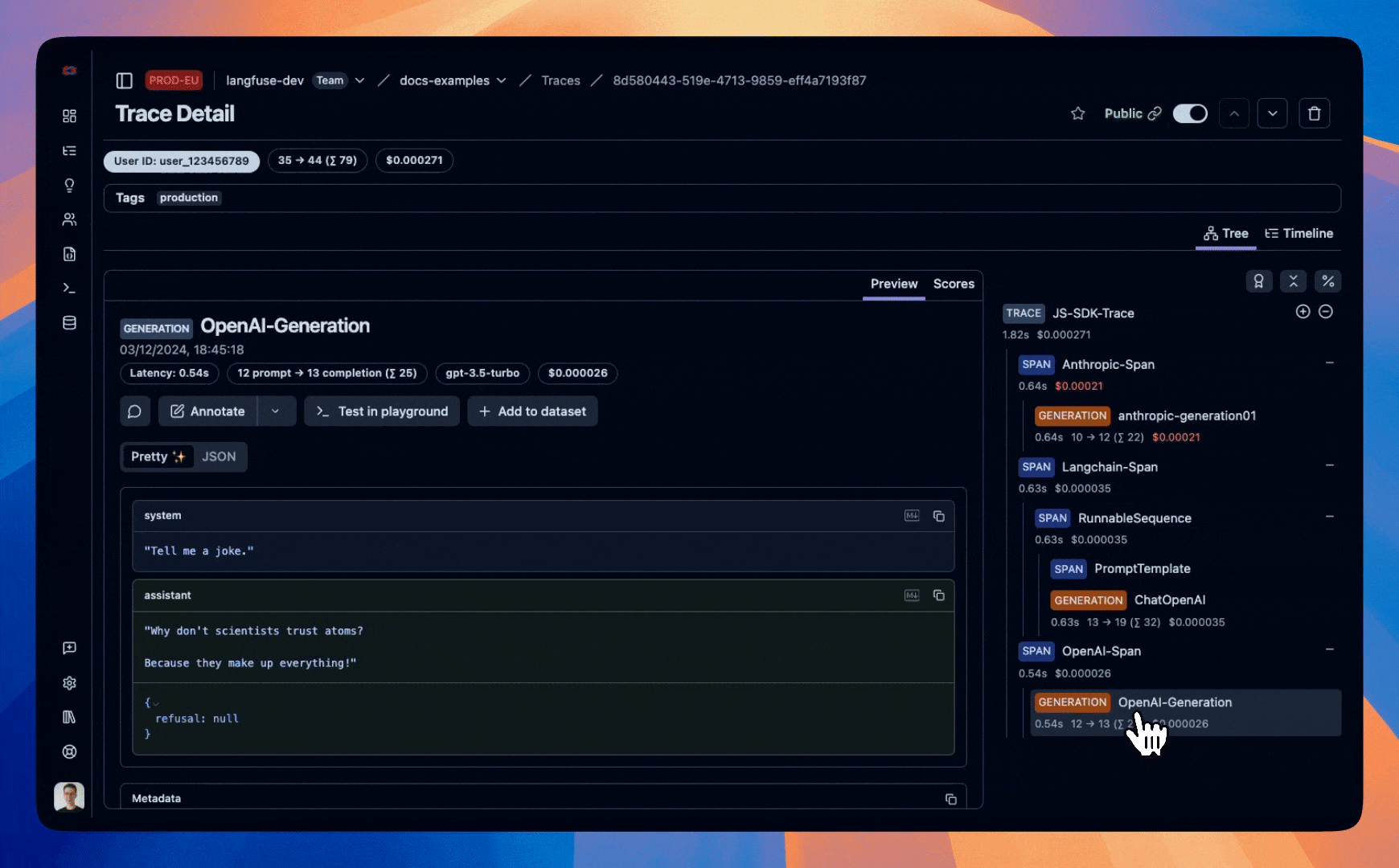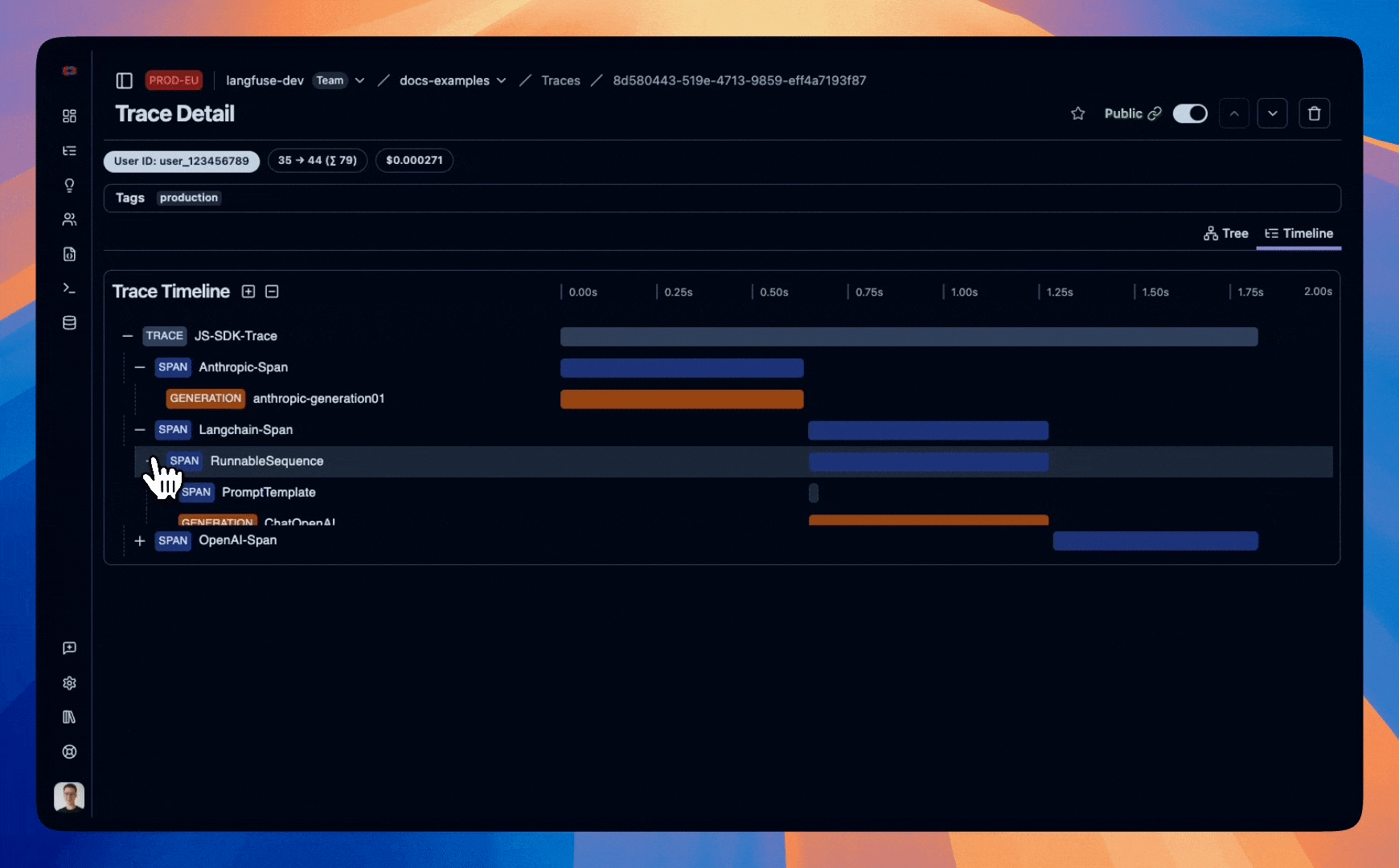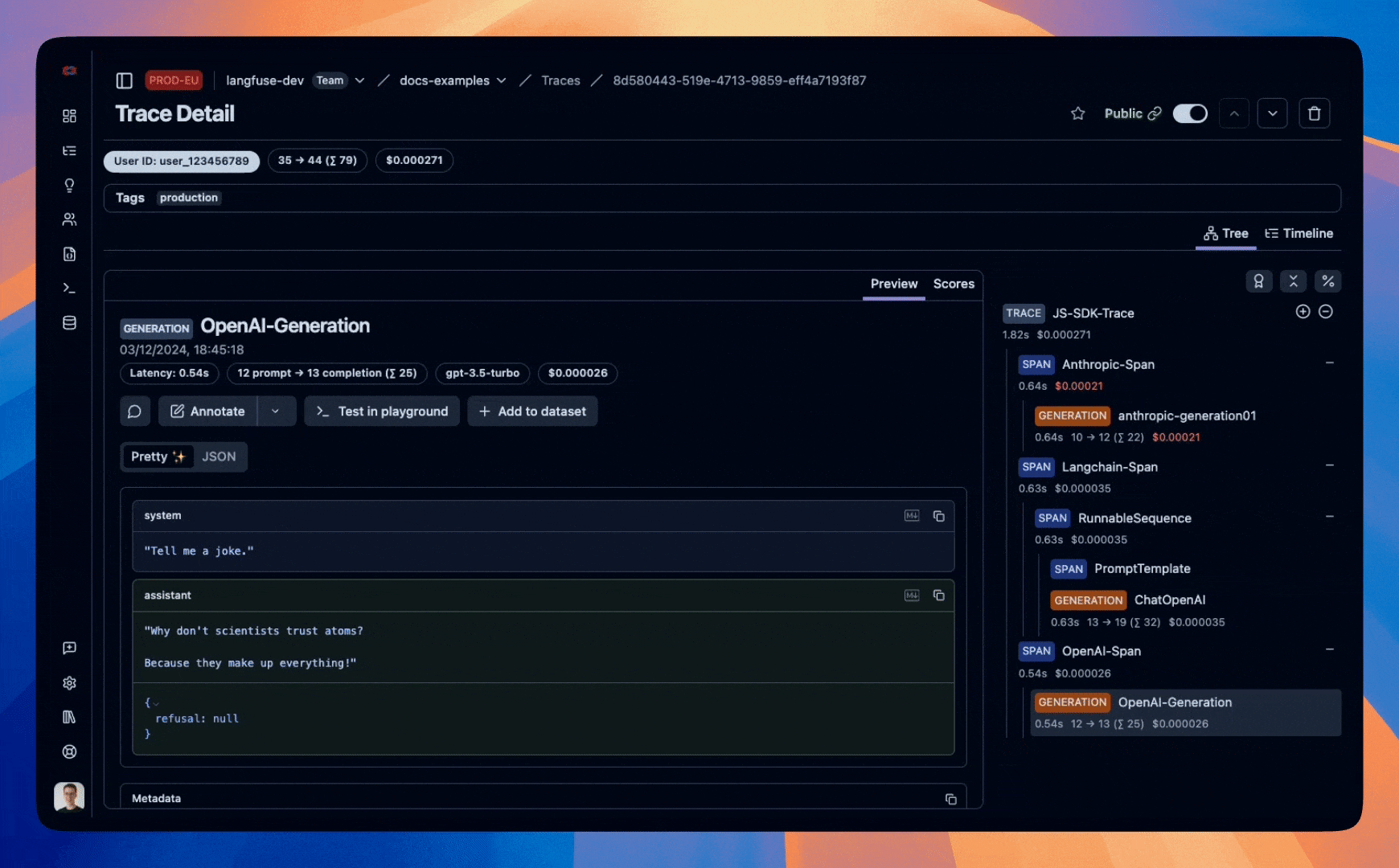
Step 1: Setup
Note: This cookbook uses Deno.js, which requires different syntax for importing packages and setting environment variables.
Set your Langfuse API keys, the Langfuse host name and keys for the used LLM providers.
See SDK Guide for more details on how to initialize the SDK.
// Set env variables, Deno-specific syntax
Deno.env.set("OPENAI_API_KEY", "sk-...");
Deno.env.set("ANTHROPIC_API_KEY", "sk-...");
Deno.env.set("LANGFUSE_SECRET_KEY", "sk-...");
Deno.env.set("LANGFUSE_PUBLIC_KEY", "pk-...");
Deno.env.set("LANGFUSE_HOST", "https://cloud.langfuse.com") // For US data region, set this to "https://us.cloud.langfuse.com"Initialize the Langfuse client.
import Langfuse from "npm:langfuse";
// Init Langfuse SDK
const langfuse = new Langfuse();Step 2: Create a Trace
Langfuse observability is structured around traces. Each trace can contain multiple observations to log the individual steps of the execution. Observation can be Events, the basic building blocks which are used to track discrete events in a trace, Spans, representing durations of units of work in a trace, or Generations, used to log model calls.
To log an LLM call, we will first create a trace. In this step, we can also assign the trace metadata such as the a user id or tags. The tracing documentation includes more details on all trace features.
// Creation of a unique trace id.
// It is optional, but this makes it easier for us to score the trace (add user feedback, etc.) afterwards.
import { v4 as uuidv4 } from "npm:uuid";
const traceId = uuidv4();// Creation of the trace and assignment of metadata
const trace = langfuse.trace({
id: traceId,
name: "JS-SDK-Trace",
userId: "user_123456789",
metadata: { user: "user@langfuse.com" },
tags: ["production"],
});
// Example update, same params as create, cannot change id
trace.update({
metadata: {
foo: "bar",
},
});Step 3: Log LLM Calls
You can use the low-level Langfuse SDK to log any LLM call or any of the integrations that are interoperable with it.
In the following, we will demonstrate how to log LLM calls using the low-level SDK, LangChain, and OpenAI integrations.
Option 1: Log Any LLM with low-level Langfuse SDK
This part shows how to log any LLM call by passing the model in and outputs via the Langfuse SDK.
Steps:
- Create span to contain this section within the trace
- Create generation, log input and model name as it is already known
- Call the LLM SDK and log the output
- End generation and span
Teams typically wrap their LLM SDK calls in a helper function that manages tracing internally. This implementation occurs once and is then reused for all LLM calls.
import Anthropic from "npm:@anthropic-ai/sdk";
const msg = "Hello, Claude";
// 1. Create wrapper span
const span_name = "Anthropic-Span";
const span = trace.span({ name: span_name });
// 2. Create generation, log input and model name as it is already known
const generation = span.generation({
name: "anthropic-generation01",
model: "claude-3-5-sonnet-20241022",
input: msg,
});
// 3. Call the LLM SDK and log the output
const anthropic = new Anthropic({ apiKey: Deno.env.get("ANTHROPIC_API_KEY") });
const chatCompletion = await anthropic.messages.create({
model: "claude-3-5-sonnet-20241022",
max_tokens: 1024,
messages: [{ role: "user", content: msg }],
});
// 4. End generation and span
// Example end - sets endTime, optionally pass a body
generation.end({
output: chatCompletion.content[0].text,
usage: {
input: chatCompletion.usage.input_tokens,
output: chatCompletion.usage.output_tokens,
},
});
// End span to get span-level latencies
span.end();
console.log(chatCompletion.content[0].text);Hello! How can I help you today?Option 2: Using LangChain
This step shows how to trace LangChain applications using the LangChain integration which is fully interoperable with the Langfuse SDK.
Since this is a native integration, the model parameters and outputs are automatically captured.
Steps:
- Create wrapper span to contain this section within the trace
- Create LangChain handler scoped to this span by passing
root - Pass handler to LangChain to natively capture LangChain traces
- End wrapper span to get span-level latencies
import { CallbackHandler } from "npm:langfuse-langchain"
import { ChatOpenAI } from "npm:@langchain/openai"
import { PromptTemplate } from "npm:@langchain/core/prompts"
import { RunnableSequence } from "npm:@langchain/core/runnables";
// 1. Create wrapper span
const span_name = "Langchain-Span";
const span = trace.span({ name: span_name });
// 2. Create Langchain handler scoped to this span
const langfuseLangchainHandler = new CallbackHandler({root: span})
// 3. Pass handler to Langchain to natively capture Langchain traces
const model = new ChatOpenAI({});
const promptTemplate = PromptTemplate.fromTemplate(
"Tell me a joke about {topic}"
);
const chain = RunnableSequence.from([promptTemplate, model]);
const res = await chain.invoke(
{ topic: "bears" },
{ callbacks: [langfuseLangchainHandler] } // Pass handler to Langchain
);
// 4. End wrapper span to get span-level latencies
span.end();
console.log(res.content)Why did the bear break up with his girlfriend?
Because she was too grizzly for him!Option 3: Using OpenAI
This step shows how to trace OpenAI applications using the OpenAI integration which is interoperable with the Langfuse SDK.
Since this is a native integration, the model parameters and outputs are automatically captured.
Steps:
- Create wrapper span to contain this section within the trace
- Call OpenAI and pass
parentto theobserveOpenAIfunction - End wrapper span to get span-level latencies
// Initialize SDKs
const openai = new OpenAI();
// 1. Create wrapper span
const span_name = "OpenAI-Span";
const span = trace.span({ name: span_name });
// 2. Call OpenAI and pass `parent` to the `observeOpenAI` function to nest the generation within the span
const joke = (
await observeOpenAI(openai, {
parent: span,
generationName: "OpenAI-Generation",
}).chat.completions.create({
model: "gpt-3.5-turbo",
messages: [
{ role: "system", content: "Tell me a joke." },
],
})
).choices[0].message.content;
// 3. End wrapper span to get span-level latencies
span.end();Step 4: Score the Trace (Optional)
After logging the trace, we can add scores to it. This can help in evaluating the quality of the interaction. Scores can be any metric that is important to your application. In this example, we are scoring the trace based on user feedback.
Since the scoring usually happens after the generation is complete, we use the user-defined trace id to score the trace.
langfuse.score({
id: traceId,
name: "user-feedback",
value: 3,
comment: "This was a good interaction",
});Step 5: View the Trace in Langfuse
Example trace in the Langfuse UI.